

Data Management Interview Questions For You (Latest)

We’ve compiled the hottest data management interview questions for 2024, along with the secret intel on why recruiters are so keen on them. You’ll discover questions that probe your strategic thinking, technical prowess, and ability to handle the ever-evolving data landscape. Why are these questions hot property in the 2024 job market? Here’s a sneak peek:
- AI and automation are reshaping Data Management
- Data Security is paramount
- Cloud is king (and queen)
- Data is the new oil, but ethics matter
Commonly Asked Interview Questions
Data management interviews in 2024 assess your technical expertise, critical thinking, and ability to navigate the evolving data landscape. Be prepared to showcase your skills with these frequently encountered questions:
- Explain the different types of data warehouses (e.g., star schema, snowflake schema, fact constellation) and their suitability for specific scenarios.
- Answer: Discuss the strengths and weaknesses of each schema in terms of query performance, data redundancy, and maintainability. Analyze the specific data structure, query patterns, and scalability requirements of the scenario to recommend the optimal approach.
- Describe your experience with data integration tools and techniques for handling diverse data sources and formats.
- Answer: Discuss tools like ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, mentioning specific tools like Fivetran or Stitch for data extraction and transformation. Explain techniques like data mapping and schema normalization for integrating heterogeneous data sources.
- How would you design a scalable and secure data lake architecture for an organization with rapidly growing data volume and diverse data types?
- Answer: Discuss using cloud-based platforms like AWS S3 or Azure Data Lake Storage for scalable storage. Mention data governance and security practices like access control, encryption, and audit logging. Explain the benefits of leveraging tools like Apache Spark or Hadoop for distributed data processing on a data lake.
- Explain the concept of event streaming and its potential applications in real-time data analytics and event-driven architectures.
- Answer: Discuss platforms like Apache Kafka or Amazon Kinesis for ingesting and processing real-time data streams. Mention applications like fraud detection, anomaly detection, and personalized recommendations that benefit from event streaming.
- How would you implement a data quality monitoring and anomaly detection framework to ensure the accuracy and integrity of data within your architecture?
- Answer: Discuss tools like DataDog or Datadog for monitoring data pipelines and data quality metrics. Mention using statistical methods and outlier detection algorithms to identify data anomalies and potential issues.
- Describe your experience with data modeling techniques and tools for designing efficient and scalable data structures.
- Answer: Discuss your understanding of dimensional modeling concepts and normalization techniques. Mention specific tools like ER diagramming software or data modeling platforms for designing data models. Showcase your experience with different database platforms (e.g., relational, NoSQL) and their suitability for specific data models.
- How would you approach implementing a self-service data platform for non-technical users to access and analyze data without relying on IT support?
- Answer: Discuss data visualization tools like Tableau or Power BI and how they empower non-technical users with self-service analytics. Mention utilizing data governance policies and access controls to ensure secure and responsible data access.
- Explain the challenges and potential solutions involved in migrating from on-premises data infrastructure to a cloud-based data warehouse solution.
- Answer: Discuss data security and compliance considerations, data migration strategies like batch processing or data streaming, and cost optimization techniques for cloud data warehousing.
- How would you measure the success of your data management strategy beyond traditional technical metrics? Discuss frameworks or key performance indicators (KPIs) you consider crucial for data-driven decision making.
- Answer: Discuss KPIs like business user adoption, time to insights, and impact on business objectives. Mention frameworks like DIKW (Data, Information, Knowledge, Wisdom) to assess the value derived from data across different stages of analysis. Showcase your understanding of the business context and ability to align data management goals with organizational outcomes.
- Share a challenging data management problem you faced and how you applied your skills and knowledge to overcome it.
- Answer: Focus on a project where your technical expertise was crucial for solving a complex data management issue. Explain the problem, your thought process, the technical solutions you implemented, and the successful outcome.

Core Concept Interview Questions
From commonly asked questions, hiring manager will move onto more job-profile oriented questions. Now is the time when you’ll be asked more specific conceptual questions that needs both basics and advanced knowledge.
1. Explain the fundamental principles of data management: Data integrity, Data security, Data availability, and Data usability.
- Answer: Discuss the importance of ensuring data accuracy and consistency (integrity), protecting data from unauthorized access (security), guaranteeing data accessibility when needed (availability), and presenting data in a way that users can understand and utilize (usability). Analyze how these principles interact and influence design decisions in data management systems.
2. Differentiate between centralized and decentralized data governance models and their implications for data control and decision-making.
- Answer: Explain how centralized models give control to a single authority, while decentralized models distribute responsibility across various stakeholders. Discuss the advantages and disadvantages of each approach in terms of efficiency, flexibility, and responsiveness to business needs.
3. Describe the concept of data lineage and its significance in ensuring data trust and transparency in complex data pipelines.
- Answer: Explain how data lineage tracks the origin and transformations applied to data throughout its journey from source to user. Discuss its importance for debugging errors, identifying data biases, and building trust in data-driven decisions. Explore tools and techniques for effective data lineage tracking in modern data architectures.
4. Compare and contrast structured, semi-structured, and unstructured data formats and their suitability for different data types and analytics applications.
- Answer: Differentiate between tabular data with predefined schema (structured), data with loose structures like JSON or XML (semi-structured), and free-form text or multimedia content (unstructured). Discuss the strengths and weaknesses of each format for specific data types and their compatibility with different analytics tools and techniques.
5. Explain the concept of data lakes and data warehouses and their respective roles in modern data storage and analysis frameworks.
- Answer: Discuss how data lakes offer flexible storage for diverse data types in raw format, while data warehouses house curated, structured data optimized for analytics. Analyze the trade-offs between scalability and processing speed, highlighting scenarios where each approach is most suitable.
6. Describe the importance of data quality and the potential consequences of poor data quality on business decisions and outcomes.
- Answer: Explain how inaccurate or incomplete data can lead to misleading analytics, flawed decision-making, and negative business consequences. Discuss data quality checks, monitoring practices, and data cleansing techniques for ensuring data integrity and preventing costly errors.
7. Explain the ethical considerations surrounding data management, including data privacy, bias, and algorithmic fairness.
- Answer: Discuss regulations like GDPR and CCPA, the risks of algorithmic bias and discrimination, and the importance of responsible data collection, utilization, and anonymization practices. Highlight the ethical principles and best practices for ensuring data privacy and responsible data management.
8. Share your thoughts on the future of data management in the context of emerging technologies like AI, blockchain, and quantum computing.
- Answer: Discuss how AI can automate data analysis and anomaly detection, blockchain can ensure data security and tamper-proof auditing, and quantum computing can revolutionize data processing for complex optimization problems. Analyze the potential challenges and opportunities these technologies present for the future of data management.
Technical Interview Questions
- Explain the different types of joins in SQL and their performance implications when querying large datasets.
- Answer: Discuss inner joins, left/right outer joins, and full joins, explaining how they handle matching and unmatched rows. Analyze the query complexity and potential performance bottlenecks associated with each join type for large datasets.
- Describe your experience with data normalization techniques and the trade-offs between different normalization levels (1NF, 2NF, 3NF, etc.).
- Answer: Explain how normalization reduces data redundancy and improves data integrity. Discuss the benefits and drawbacks of each normalization level, highlighting the impact on storage efficiency, query performance, and update complexity.
- How would you approach optimizing the performance of a slow-running SQL query in a production environment?
- Answer: Discuss analyzing the query execution plan, identifying bottlenecks like inefficient joins, indexing strategies, or suboptimal table structures. Explain techniques like index tuning, rewriting the query logic, or partitioning data for improved performance.
- Explain the differences between ACID and BASE transactions and their suitability for different data management scenarios.
- Answer: Discuss Atomicity, Consistency, Isolation, and Durability (ACID) properties for ensuring data integrity in transactions. Compare it to BASE (Basically Available, Soft-state Eventual consistency) principles used in distributed systems, highlighting their trade-offs in consistency versus availability.
- Describe your experience with NoSQL databases and their advantages compared to traditional relational databases for specific data types or use cases.
- Answer: Discuss various NoSQL database types like document stores, key-value stores, and graph databases. Explain their scalability, flexibility, and suitability for handling unstructured data, high-velocity data streams, or complex relationships.
- Explain the concept of data partitioning and its benefits for distributed data processing in platforms like Hadoop or Spark.
- Answer: Discuss how data partitioning divides large datasets into smaller, manageable units for parallel processing. Explain the benefits of improved query performance, load balancing, and fault tolerance in distributed environments.
- Describe your experience with data security and encryption techniques used to protect sensitive information in data warehouses and data lakes.
- Answer: Discuss data encryption at rest and in transit, mentioning specific algorithms like AES or RSA. Explain access control mechanisms like role-based access control (RBAC) and attribute-based access control (ABAC) for data security.
- How would you handle data quality issues like missing values, outliers, and inconsistencies within a data pipeline?
- Answer: Discuss data validation techniques, outlier detection algorithms, and imputation methods for handling missing values. Explain data cleansing processes and data quality monitoring tools to ensure the accuracy and integrity of data throughout the pipeline.
- Describe your experience with data compression techniques and their role in optimizing data storage and network bandwidth usage.
- Answer: Discuss lossless and lossy compression algorithms like ZIP or BZIP2 for data files. Explain how compression reduces data storage footprint and network bandwidth requirements, especially for large data sets.
- Explain the challenges and best practices for implementing data versioning and data lineage tracking in complex data pipelines.
- Answer: Discuss the importance of versioning data sets to track changes and allow rollbacks. Explain lineage tracking tools and frameworks for documenting the origin and transformations applied to data throughout the pipeline. Highlight the benefits for debugging data errors, ensuring compliance, and building trust in data-driven decisions.
Remember, these are just starting points. Tailor your answers to showcase your specific technical skills, knowledge of different tools and technologies, and problem-solving abilities.
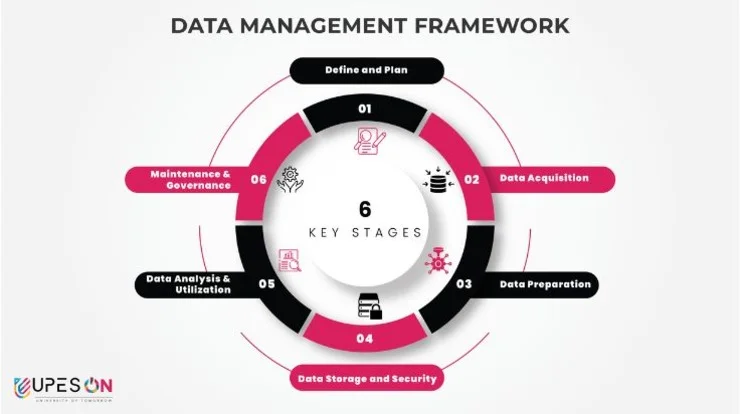
In-depth Interview Questions
Basics are good but hiring managers will go beyond core concepts and delve into your ability to apply expertise and analyze complex scenarios. Here’s what you need to be prepared for:
1. Design a data analytics pipeline for a streaming platform like Netflix or Spotify, considering real-time processing, anomaly detection, and personalized recommendations.
- Answer: Discuss using Apache Kafka or similar platforms for ingesting real-time user activity data. Explain anomaly detection algorithms to identify suspicious behavior or sudden spikes in activity. Explore collaborative filtering and matrix factorization techniques for generating personalized recommendations based on user preferences and historical data.
2. How would you approach implementing a self-service data analysis platform while ensuring data security and governance in a multi-cloud environment?
- Answer: Discuss utilizing cloud-based data platforms like Amazon Redshift Spectrum or Azure Synapse Analytics for scalable data access and analysis. Explain cloud access security brokers (CASBs) and data governance tools for controlling user permissions and enforcing data security policies across different cloud providers.
3. You’re tasked with optimizing a large-scale data warehouse experiencing performance bottlenecks. Describe your diagnostic and optimization strategies.
- Answer: Discuss analyzing query execution plans and identifying inefficient joins, indexes, or materialized views. Explain data partitioning techniques and columnar storage options for improved performance. Consider cost optimization strategies like leveraging serverless functions for temporary workloads.
4. Design a data management strategy for a company facing rapid data growth and diverse data types, including structured, semi-structured, and unstructured data.
- Answer: Explore hybrid data architectures utilizing data lakes for flexible storage of raw data and data warehouses for curated, structured data analysis. Discuss integrating NoSQL databases for handling specific data types like JSON or graph data. Explain data lake governance and data quality monitoring practices for managing diverse data effectively.
5. Analyze the potential impact of blockchain technology on data management, specifically regarding data security, provenance, and decentralization.
- Answer: Discuss how blockchain’s immutable ledger can enhance data security and transparency. Explain the concept of smart contracts for automated data provenance tracking and verification. Analyze the challenges and opportunities for decentralizing data storage and control using blockchain technology.
6. Explain the trade-offs between traditional relational databases and modern cloud-based data warehouses like Snowflake or BigQuery in terms of scalability, flexibility, and cost.
- Answer: Discuss the limitations of relational databases for scaling with large datasets and the elasticity offered by cloud data warehouses. Analyze the pay-as-you-go pricing of cloud solutions versus upfront costs of on-premises infrastructure. Highlight the trade-offs in flexibility and customization options when moving to cloud-based data storage.
7. You’re facing a data bias issue in an AI model trained on your company’s data. Explain your approach to identifying and mitigating this bias.
- Answer: Discuss data analysis techniques to identify biased data patterns, such as analyzing demographics and identifying underrepresented groups. Explain data augmentation and rebalancing techniques for correcting biased datasets. Emphasize the importance of responsible data collection practices and ongoing monitoring to prevent bias in future models.
8. Describe your experience with advanced data modeling techniques like dimensional modeling, data vault modeling, and star schema variations.
- Answer: Discuss the strengths and weaknesses of each data modeling approach and its suitability for specific data types and query patterns. Explain your experience with tools like ER diagramming software or data modeling platforms for designing efficient and scalable data models.
Situational Interview Questions
Stuck in a situation where your decision will decide the future of business, well recruiters will like to know to exactly the same. What you would do in a particular situation, how would you react to challenges and what are the steps you’ll take to ensure the problem is identified and resolved.
1. You’re the data lead for a growing e-commerce company experiencing unexpected spikes in website traffic. How would you diagnose the cause and design a data management solution to ensure website stability and customer experience?
- Answer: Discuss analyzing server logs, website analytics, and network traffic data to identify the source of the traffic spikes. Consider potential causes like bot attacks, social media campaigns, or product promotions. Explain implementing scalable data pipelines and utilizing tools like cloud-based data platforms or serverless functions to handle increased data volume without affecting performance. Emphasize real-time monitoring and alerting systems to prevent future outages and ensure seamless customer experience.
2. Your company plans to launch a personalized recommendation engine. What data sources would you consider using, and how would you design the data processing pipeline to generate accurate and relevant recommendations?
- Answer: Discuss user purchase history, browsing behavior, demographics, and product attributes as potential data sources. Explain utilizing data profiling techniques and collaborative filtering algorithms to identify user preferences and recommend similar products. Mention incorporating data quality checks and feedback mechanisms to refine the recommendation engine over time.
3. You’re migrating your company’s data warehouse from on-premises infrastructure to the cloud. What factors would you consider when choosing a cloud provider and designing the migration strategy?
- Answer: Discuss cost, scalability, security features, and compatibility with existing tools and data formats when choosing a cloud provider. Explain outlining a phased migration plan to minimize disruption and maintain data integrity. Mention utilizing data migration tools and cloud-native services for efficient and secure data transfer.
4. You’re tasked with improving the data literacy of your company’s non-technical employees. What training programs or tools would you recommend to empower them to use data effectively in their daily work?
- Answer: Discuss offering data visualization tools like Tableau or Power BI for easily understanding reports and dashboards. Introduce basic data analysis concepts like averages, trends, and correlations. Recommend online training courses or data storytelling workshops to build confidence and encourage data-driven decision-making across all departments.
5. You discover a data security breach within your company’s infrastructure. How would you handle the situation and ensure it doesn’t happen again?
- Answer: Discuss immediately notifying relevant authorities and internal security teams. Explain isolating the affected system and preventing further data exposure. Analyze the breach to identify the source and vulnerabilities exploited. Outline a remediation plan to patch vulnerabilities, enhance security protocols, and implement data loss prevention measures. Emphasize the importance of ongoing security training and continuous vulnerability assessments to prevent future breaches.
This article doesn’t just drop you in the interview arena unarmed. We have relevant certifications that’ll make your data resume sing like a siren. Think of them as your secret decoder rings to unlock hidden career opportunities. So, get your data backpack, grab your skills map, and let’s embark on this epic quest together! Master the interview questions, level up your skills, and emerge as the data hero employers are eager to recruit.
Recommended Blogs

7 Surprising Benefits of an MBA in Oil and Gas Management
An MBA in Oil and Gas Management helps you advance your career with Leadership Skills, Networking, Global Knowledge, Professional Growth.
Read MoreMar 15, 2024 I 2 minutes
45+ Business Development Interview Qs! (Basic, Concepts, Tech)
Master your Business Development interview prep with 45 most asked questions for freshers, experienced & techies. New Questions updated!
Read MoreFeb 16, 2024 I 10 minutes
Introduction to Renewable Energy Management: What You Need To Know
Discover what is renewable energy management, its importance to the world and the key aspects of managing these energy sources.
Read MoreJan 20, 2023 I 2 minutes
Ace Your Data Governance Interview with these 55 Question Types
Master 55 data governance interview Questions, from data lineage puzzles to AI challenges. Sharpen your skills & land your dream data role.
Read MoreJan 21, 2024 I 15 minutes